XHTML considered harmful
This page is a mirrored copy of an article originally posted on the (now sadly defunct) LShift blog; see the archive index here.
Mon, 3 April 2006
… in at least one common scenario. Here’s a summary:
- Problem: Empty textareas written
<textarea />break both Firefox[1] and IE6. - Solution: Remove all mention of XHTML from your documents and XSLT stylesheets, and continue using XHTML-like XML without pain.
For details and explanation, read on.
For your delectation, one small piece of hard-won, expensive knowledge: if you supply XHTML (ie. a document root “html” in the XHTML 1.0 namespace) to Xalan for processing by an XSLT stylesheet, it will treat it as XML, and print it as XML. There is nothing you can do to make it print it as HTML 4.01 (in other words, Appendix C of the XHTML spec is ignored). On the other hand, if you supply XHTML-like XML (ie. a well-formed XML document with a document root “html” in no namespace at all) to Xalan, it will happily parse it, and will print it as HTML 4.01. This is a crucial thing to know if you are trying to build (X)HTML from some input source to send to browsers that are expecting HTML formatting conventions, such as IE6 and, in some circumstances, even Firefox.
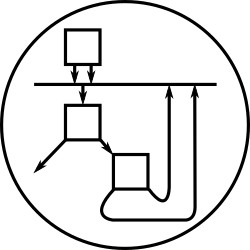
Forgive the ASCII-art - here’s a diagram of the render pipeline I was attempting:
XHTML template +
custom tags +
field binding specs
|
| XSLT (1)
V
XHTML template +
field binding specs
|
| XSLT (2)
V
XML field -------> XSLT stylesheet -------> XHTML for display
values |
|
V
User Agent
Transformation 1 expanded application-specific tags, generating boilerplate for page headers/footers etc. Transformation 2 turned the XHTML template with lshift:field binding attributes into an XSLT stylesheet that was prepared to accept an XML document containing field details and that would in turn emit an XHTML document based on the original template, with the field values from the source XML document spliced in.
The two major problem elements are empty <script> tags and empty <textarea> tags. If IE6 sees a script tag that looks like “<script />“, it (correctly[2], for HTML!) interprets this as an unclosed script tag, and processes the rest of the document as if it were a script. Firefox decides the page author has made an understandable mistake and displays the document as (probably) intended. You can work around the problem, often, by supplying some non-empty text to go in the otherwise empty script tag: a single semicolon will do. This can be automated as part of transformation 2 in the diagram above.
Textareas are more of a problem. Supplying any content for the element obviously has a different meaning to supplying no content for the element - and if either Firefox or IE see “<textarea />“, they interpret the entire remainder of the document as the content of the textarea, since HTML formatting conventions require that empty textareas are to be written “<textarea></textarea>“.
After several hours spent breaking myself on the rocks of XHTML-in-the-real world trying to get Xalan to print empty scripts and textareas according to HTML convention[3], a good night’s sleep and some prompting by my colleague mikeb focussed me on the differences between the system I was trying to get working and the working example HTML I had been following. Close examination and a couple of small experiments showed the significant difference to be the lack of a namespace in the working HTML-like XML. Presto: I removed all mention of XHTML from my documents and stylesheets and everything worked as if by magic.
To sum up: Just Say No to using the XHTML namespace with Xalan. You’re welcome to continue using something that looks remarkably like XHTML - just make sure it isn’t in a namespace. Xalan seems to have poorly-documented magic in it in this area.
On the other hand, if you can guarantee that whatever you’re targetting truly can read XHTML properly, then go for it - of course, that excludes almost all browsers in the market…
Footnote 1: You can make Firefox interpret <textarea /> sensibly, but it is dependent on the fine alignment of a number of variables and major planets. Setting the correct content-type is also important.
Footnote 2: HTML, an SGML application, apparently (according to hearsay on the internet) interprets <tag/> as <tag>> according to some strict reading of the specification.
Footnote 3: An optimist might have expected <xsl:output method="html"/> to help. It doesn’t. You need both the html output-method and non-namespaced XHTML-like XML in order to get the desired <textarea></textarea> effect.
Comments
On 3 April, 2006 at 5:23 pm, wrote:
On 3 April, 2006 at 5:31 pm, wrote:
“The html output method should not output an element differently from the xml output method unless the expanded-name of the element has a null namespace URI.�?
Thank you! I missed that in my frustrated reading and re-reading of the spec last night. That actually does take a lot of the apparent magic away from the situation.
On 8 September, 2006 at 2:43 pm, wrote:
In an XSTL style sheet just use the zero-width, non-breaking space as content between the tags:
Hans-Georg
p.s. My email address is only valid through 2006. Guess the next. (:-)
On 8 September, 2006 at 2:45 pm, wrote:
Oh, the stupid web forum software ate my example!
Here it is (I hope):
–>]]>
Hans-Georg
On 8 September, 2006 at 2:46 pm, wrote:
So stupid!
< t e x t a r e a … > & # 6 5 2 7 9 ; < / textarea >
Hans-Georg
On 11 September, 2006 at 2:03 pm, wrote:
Nice tip, Hans-Georg; I’ll have to remember that one.
On 23 April, 2007 at 12:15 pm, wrote:
Unfortunately (yet naturally) the character remains in the textarea, so you have to get rid of it somehow.
Yes, it’s better than nothing (and you can erase it using JS so that user doesn’t notice anything), but still…
Nonetheless thanks a lot Hans-Georg!
On 25 April, 2007 at 6:46 pm, wrote:
Of course, there is another reason for not using XHTML — if you can’t serve it as XHTML (IE doesn’t understand it, etc.) you may as well be doing HTML anyway.
In that case you end up doing an HTML-like XML (but not HTML, since it can’t be put though XSLT); i.e., pretty much what Tony proposed in the first place.
On 11 August, 2007 at 11:37 am, wrote:
Someone suggested which works better than the suggestions about non-breaking zero width spaces and the like. Most browsers render these funny characters as “?” whereas comes out as a gloriously invisible space - not perfect for all uses but good enough for me. Switching everything to HTML is also unattractive, if you are trying to generate XHTML that is. The fault is not Xalan but the browsers. is equivalent to and should be treated as such.
On 11 August, 2007 at 11:40 am, wrote:
my xml didn’t come out: I meant to insert “<textarea><xsl:text> </xsl:text></textarea> after “suggested”.
I don’t think it’s magic at all. The XSLT specification says (http://www.w3.org/TR/xslt#section-HTML-Output-Method):
“The html output method should not output an element differently from the xml output method unless the expanded-name of the element has a null namespace URI.”
Further, if an element is null-namespaced and recognised as an HTML element (case-insensitively), then it is treated as HTML with all the accompanying rules for empty elements and so on.
Bear in mind that XSLT was specified a year /before/ XHTML. Sure, developers can always make up for it by implementing some DWIM feature— but then there really would be some (possibly undocumented) magic.
That’s not true. You can transform it to null-namespaced HTML using something like:
<xsl:template match="xhtml:*"> <xsl:element name="{local-name()}"> <xsl:copy-of select="@*/> <xsl:apply-templates/> </xsl:element> </xsl:template>